Clapgrep lets you search through directories containing all kinds of text, PDF and Office documents.
It you didn’t know about it yet, you can
Table of Contents
Open Table of Contents
First some cosmetic updates
The search button is now a proper primary button and the search path is displayed using a more appropriate component. It also now shows the full path instead of just the directory name, which can come in handy when the name alone is not unique.
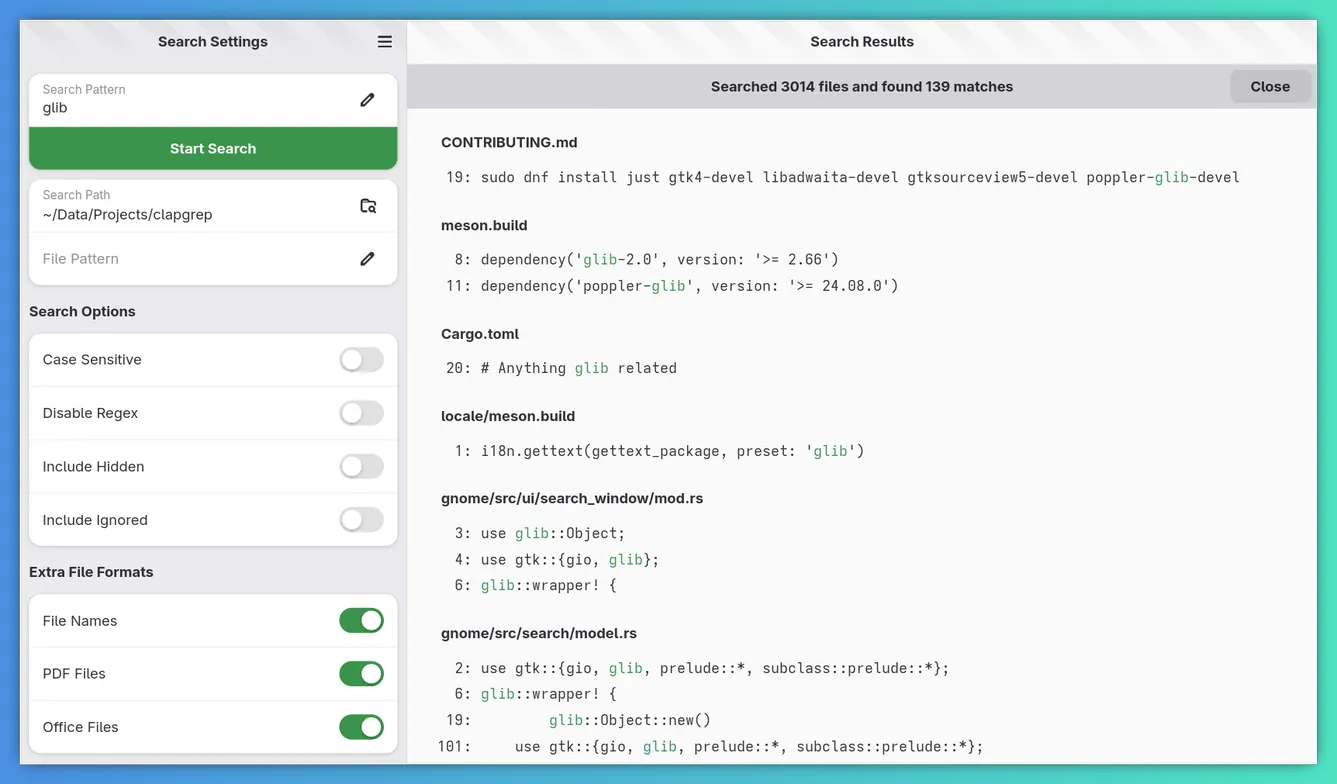
File and path globbing
You now have much more fine-grained control over which files and paths will be searched using Unix shell style glob patterns. This means you can do things like:
*.rswill only search Rust source files.*.pdfwill only search PDF files.*test*will only search files containing “test”.
If you also activate the new explicit path matching. The equivalent to the ones above now has to look like this:
**/*.pdfwill only search PDF files.
Where is the advantage you might ask? Well, it means you can also
**/src/**/*only search for files somewhere within asrcdirectory.*will search for files at the selected directory.*/*will only search for files with a depth of 1.*/*/*will only search for files with a depth of 2, and so on.
So happy globbing!
No more infinite memory usage!
When running a very broad query on a huge directory with millions of matches, Clapgrap previously just chonked away at your memory leaving even Chrome and the likes behind in the dust. Now Clapgrep got some more conscience and will stop the search automatically when you have more than a thousand results by default. You can also adjust this limit to anything between a hundred and 10k results in the new preferences dialog.
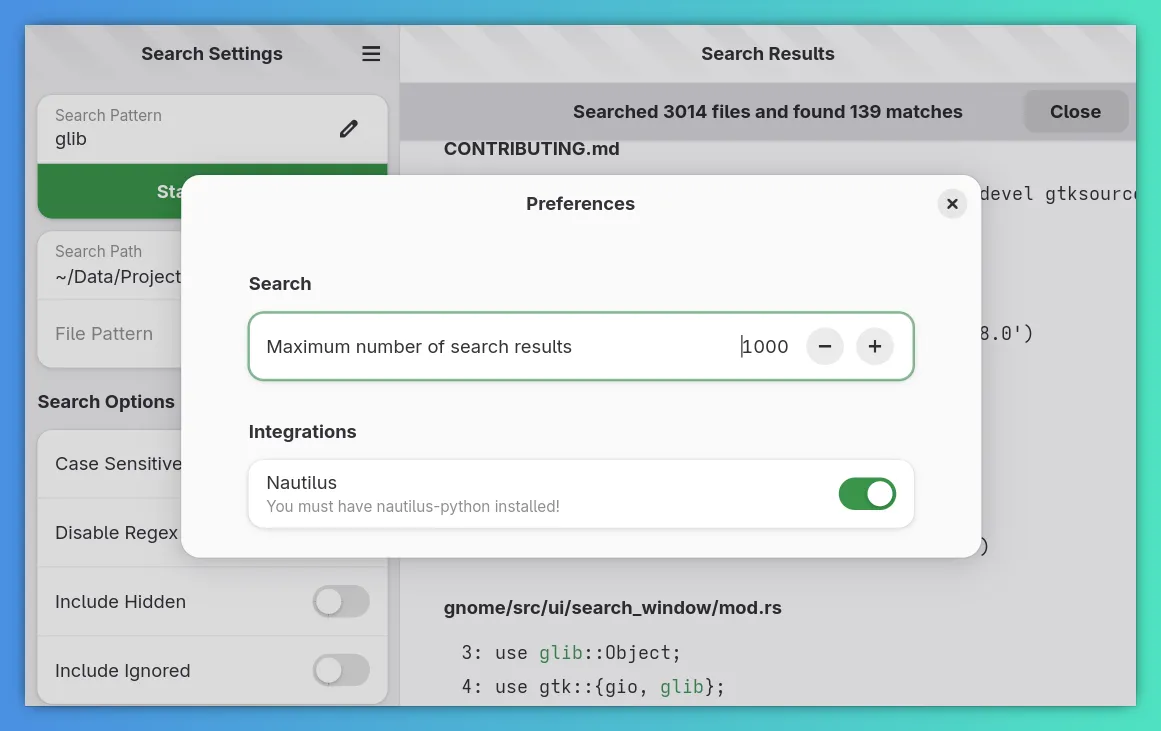
An installer for the Nautilus extension
As you might have spotted in the screenshot above, there is now a switch to install the Nautilus extension. This extension has actually been around for quite some time, but as I had nowhere to put the installer, there was no installer and thus nobody got to know about it or use it :(
But now you can easily install it, which will provide you with the following new options in Nautilus:
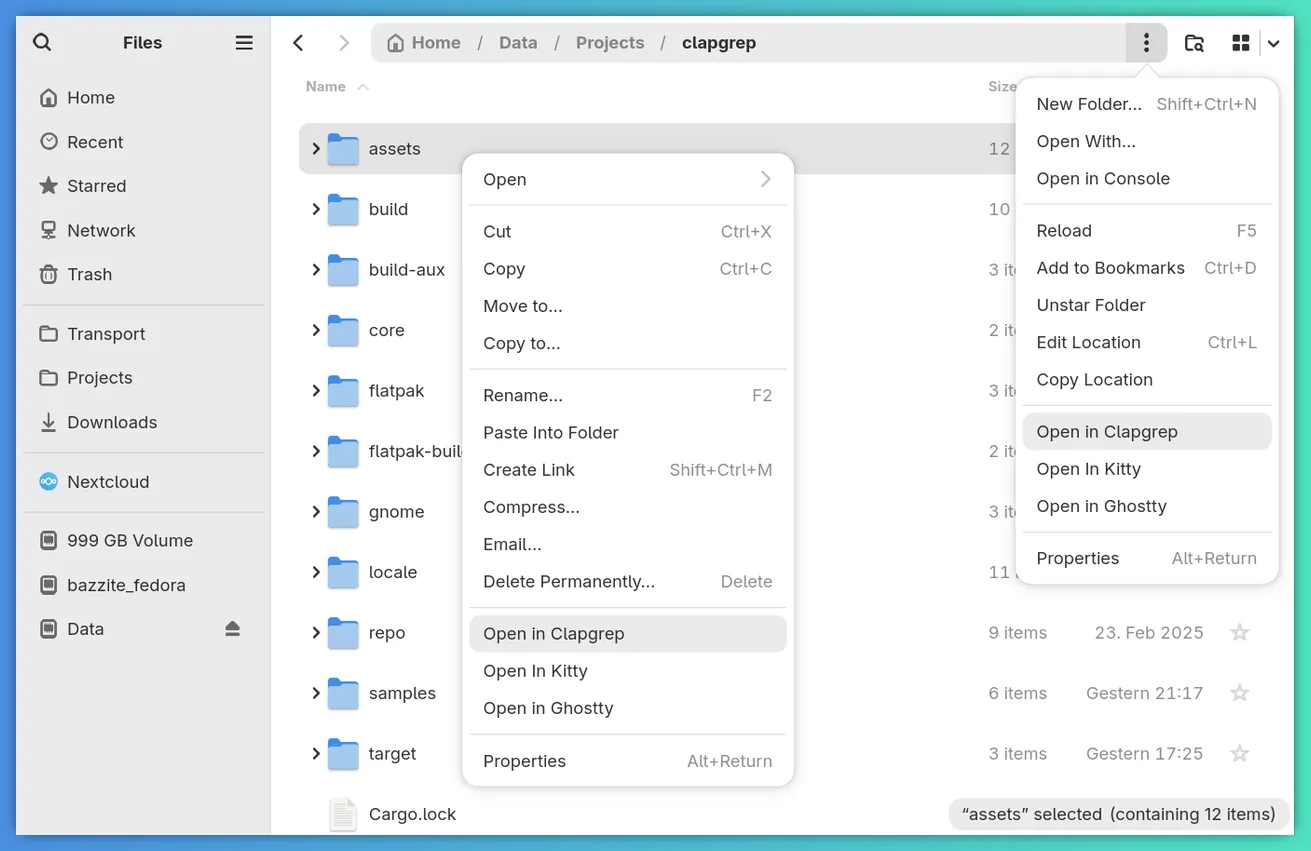
Note that you’ll have to install the nautilus-python package and either reboot or kill Nautilus for this to show up.
Presentation results numbered by slide
Previously, the line numbers of Libre/MS Office documents made no sense at all. Now they still don’t make sense for most of them! Well, except for presentations at least, where they now show on which slide something was found.
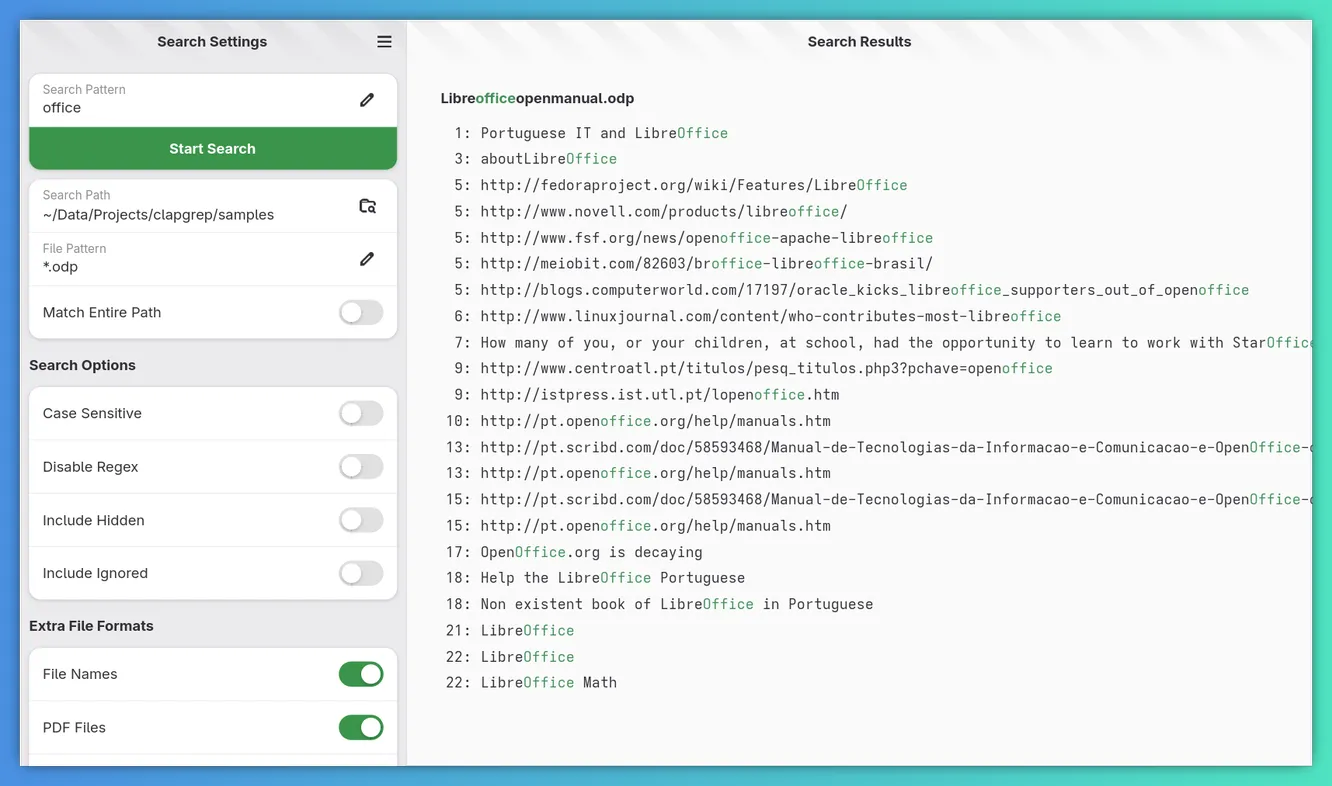
For text documents things are a bit difficult. Page numbers will be expensive to calculate and for MS Office documents likely also inaccurate. The reason for this is that DOCX and ODT documents don’t really have pages. They are just one huge continuous document and only the editor puts some space in-between the “pages” it displays. As such, showing the correct page number in Clapgrep would involve rendering the document using LibreOffice to a PDF and then query that in a paginated manner. And for this to be viable I’ll at least have to implement caching first. For spreadsheets, I can’t think of a reasonable numbering at all, so I think I’ll just remove the numbers in the future.
Keyboard focus got nicer
Previously, if you wanted to tab through the search results after starting a search, you would have to first tab through all the search settings. Now, when you hit enter, the focus will immediately jump to the results, making keyboard navigation a lot faster.
It’s sadly still not possible to focus the headings using the keyboard, which might be breaking accessibility. I’m tracking this bug in #108, but I think it’s going to be a lot of work to fix it.
New and updated translations
And lastly, a thank you to those who helped to improve the translations even though I still haven’t setup proper translation infrastructure: